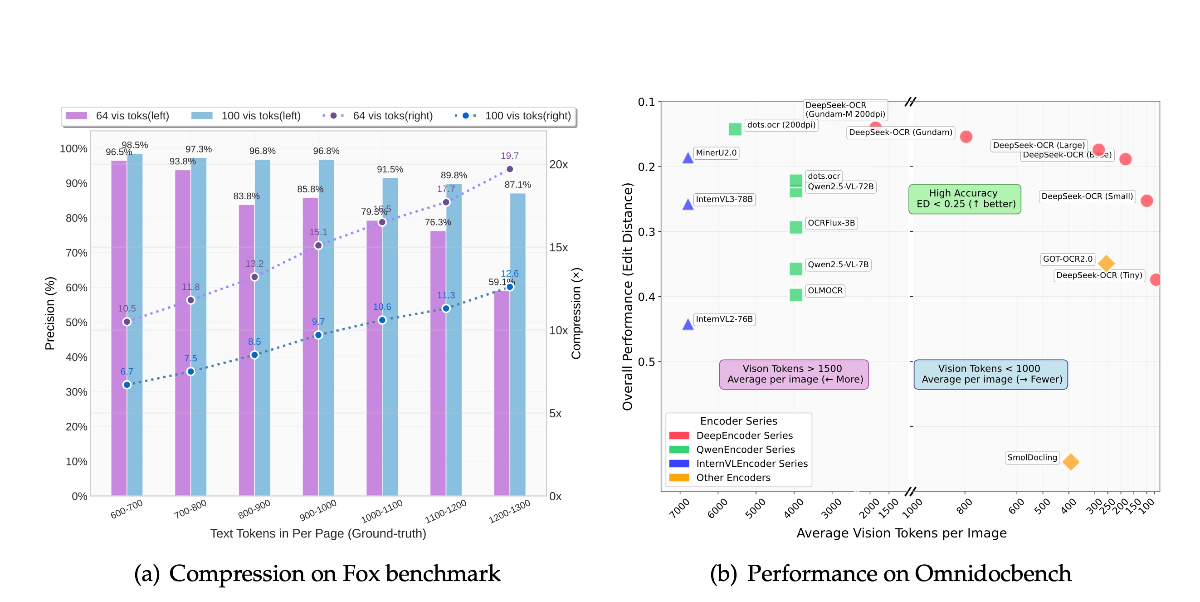
NeuTTS Air:离线语音合成的革命性突破
在AI技术飞速发展的今天,语音合成早已不是新鲜事。但大多数TTS工具都依赖云端服务,不仅需要网络连接,还存在隐私泄露风险。Neuphonic公司推出的NeuTTS Air开源模型彻底改变了这一局面,它是一款能在本地设备离线运行的高质量语音合成工具,仅需3秒音频就能克隆任何人声,真正实现了"口袋里的配音演员"。
官网地址:项目开源地址位于GitHub的neuphonic/neutts-air仓库
✨ 核心功能亮点
- 超高拟真度:合成语音自然流畅,几乎达到以假乱真的程度
- 完全离线运行:不依赖网络,手机、笔记本电脑甚至树莓派都能流畅使用
- 3秒声音克隆:只需极短的音频样本,就能完美复刻任何人声特征
- 多平台兼容:支持GGML格式,跨平台部署无压力
- 实时推理能力:中端设备上也能实现即时语音生成
- 隐私安全保护:数据完全留在本地,杜绝云端泄露风险
技术架构解析
NeuTTS Air的成功离不开其创新的LM + Codec混合架构。简单来说,这个系统就像两位专业配音员的完美配合:一位负责理解文本含义(语言模型),另一位负责声音呈现(编解码器)。
技术核心基于Qwen 0.5B语言模型负责文本理解,确保发音准确、语调自然;自研的NeuCodec音频编解码器则专注于声音质量,采用单码本结构在保证音质的同时大幅降低计算需求。这种分工协作的模式,让NeuTTS Air在有限的硬件资源上实现了专业级的语音合成效果。
特别值得一提的是GGML格式的支持,这使得模型能够高效运行在各种CPU设备上,从高性能电脑到嵌入式开发板都能流畅使用,真正实现了"一次训练,随处部署"。
深度评测与竞品对比
核心优势
- 隐私保护极致化:所有数据处理都在本地完成,适合医疗、司法等敏感领域
- 部署灵活性极高:从服务器到移动设备全面覆盖,树莓派也能流畅运行
- 声音克隆效率惊人:仅需3秒样本就能完成声音复制,速度快得离谱
- 生成质量出众:在中端设备上就能产出接近真人水平的语音
- 成本控制优秀:完全开源免费,长期使用成本几乎为零
明显短板
- 硬件要求不低:虽然支持多种设备,但低配硬件上生成速度会明显变慢
- 声音库有限:需要自行准备克隆样本,不如云端服务开箱即用方便
- 技术门槛存在:本地部署需要一定的技术基础,对小白用户不够友好
- 多语言支持一般:主要优化了中文场景,其他语言效果有待提升
竞品对比分析
| 对比维度 | NeuTTS Air | Azure Neural TTS | Google WaveNet | Meta Voicebox |
|---|---|---|---|---|
| 离线能力 | 完全支持 | 需联网 | 需联网 | 需联网 |
| 隐私保护 | 极致安全 | 数据上云 | 数据上云 | 数据上云 |
| 费用成本 | 完全免费 | 按量收费 | 按量收费 | 研究用途 |
| 声音克隆 | 3秒快速克隆 | 需要大量样本 | 不支持 | 需要训练 |
| 部署难度 | 中等 | 简单 | 简单 | 困难 |
| 音质表现 | 接近真人 | 商业级 | 商业级 | 实验级 |
竞品特点总结:
- Azure和Google的解决方案适合追求稳定、易用的企业用户,但持续使用成本较高
- Meta Voicebox在学术研究方面更有价值,但实用性和易用性不足
- NeuTTS Air在隐私保护和长期成本方面优势明显,特别适合对数据安全要求高的场景
实际应用场景
智能家居控制:在没有网络的郊外别墅,照样能用语音控制家电。你的离线语音助手永远不会因为断网而"罢工"。
儿童智能玩具:把孩子喜欢的童话书变成有声读物,甚至用家长的声音讲故事。这种个性化体验是传统玩具无法提供的。
移动应用集成:旅行时在信号盲区,手机导航依然能清晰播报路线。真正的"断网也能用"的语音导航。
专业隐私领域:医生问诊、法律咨询、心理辅导等敏感场景,客户录音完全留在本地设备,杜绝任何泄露风险。
内容创作利器:视频博主可以用自己的声音生成多语言版本,或者为不同角色配音,大幅提升创作效率。
未来展望
随着边缘计算设备的性能提升,像NeuTTS Air这样的离线AI工具将迎来爆发式增长。隐私保护意识的增强和网络覆盖不均的现实困境,都在推动着本地化AI应用的发展。
目前该项目在GitHub上持续更新,社区活跃度较高。对于开发者而言,现在入手学习正当时——既能享受开源技术的红利,又能提前布局隐私优先的AI应用生态。
无论你是个人开发者想要集成语音功能,还是企业用户寻求安全可靠的TTS方案,NeuTTS Air都值得你深入了解。毕竟,在数据安全日益重要的今天,能够完全掌控自己数据的AI工具,才是真正面向未来的选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...